Feast
Feast
What is Feast?
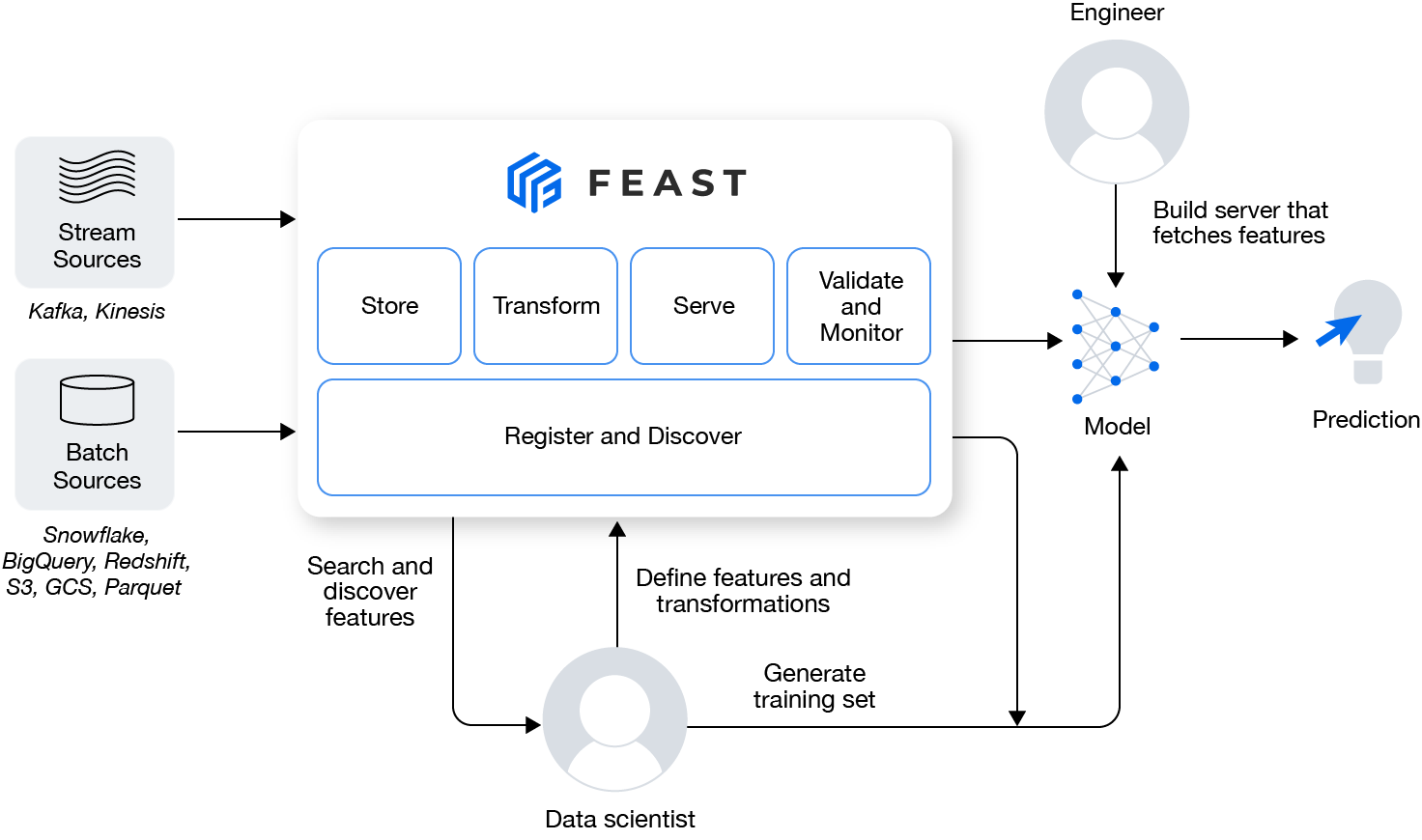
Feast 는 모델에 들어가는 머신러닝 피처를 관리하고 서빙해주는 데이타 운영 시스템. 피스트는 low latency 온라인 스토어로 실시간 예측 혹은 오프라인 스토어로 배치 채점 혹은 모델 훈련에 사용이 된다.
Problems Feast Solves(왜 써야하나)
모델들은 일관된 데이터 접근이 필요: 전통적인ML 시스템은 데이타 인프라(DB, object storage, stream 그리고 file)에 커플링 되어있는 형태가 많다. 이러한 커플링으로 인해, 어느 하나의 데이타 인프라의 변경이 일어날 경우 이러한 인프라에 의존하는 ML 시스템이 무너지게 될 수 있다. 또다른 도전과제는 훈련과 서빙을 위해 필요한 데이터를 가져올때 똑같은 코드를 두번 구현하는 문제가 있고 이러한 코드는 데이타가 일관되지 않을 수 있는 문제가 생길 수 있다, 즉 훈련 모델과 서빙 모델 간 skew 가 생기게 될 수 있다.
Feast 는 데이타 인프라와 모델을 디커플링 시켜준다. 이러한 디커플링은 단일 데이타 접근 게이어를 두어 피처 스토리지로부터 피처를 획득하는 과정을 추상화 해준다. Feast 는 또한 일관된 피처 데이타를 가져올 수 있는 레퍼런스 방식을 가지고있어서 훈련 모델을 서빙 모델로 쓸 수 있도록 보장해준다.
프로덕션에 새로운 피처들을 배포하기 쉽지않음: 많은 ML 팀은 서로 다른 목적을 가지고 있는 경우가 많다. 예를들면 DS(데이타 사이언티스트)는 피처들을 프로덕션에 빨리 배포하고싶어 하지만, 엔지니어들은 프로덕션이 stable 하기를 바라는 경우가 많다. 이렇게 다른 목적을 가지고 있는 조직들은 서로 마찰이 생기게 되어 새로운 피처를 출시하기까지의 시간을 늦추게 된다.
모델은 point-in-time 정확한 데이타가 필요하다: 프로덕션에서의 ML 모델은 훈련했던 데이타와 일관되어야한다, 그렇지 않다면 모델 정확도가 떨어지게될 수 있다. 이러한 부분을 알고있음에도, 많은 데이타 사이언스 프로젝트들은 미래에 생기는 피처들의 데이타가 일관되지 않아 모델 훈련도중에 피처 값이 누락되는 문제로 인해서 고통 받고있다.
Feast 는 데이타 누락문제를 모델 훈련을 위한 피처 데이타셋을 가져올때 point-in-time 정확한 피처 획득 기능을 제공함으로써 해결한다.
피처가 여러 프로젝트에서 재사용이 필요하다: 조직 내의 서로 다른 팀들은 여러 프로젝트에서 피처를 재사용하지 않는 경우가 있다. 사일로 문화 그리고 모놀리식 디자인으로 된 e2e ML 시스템으로 인해 중복된 피처 생산과 중복된 피처 사용을 하게 된다.
Feast 는 이러한 문제를 DS가 중앙화된 레지스트리와 서빙레이어에 피처를 발행할 수 있는 기능을 제공함으로써 해결한다. 이 레지스트리는 다른 프로젝트를 하고있는 여러 팀들이 피처 기여를 할 수 있을 뿐만 아니라 피처를 재사용할 수 있게 해준다. Feast 를 통해 DS 는 새로운 ML 프로젝트를 시작해서 이전에 엔지니어링 헀던 피처를 중앙 레지스트리에서 그대로 가져와 쓸 수 있고 각각의 모든 프로젝트에 매번 새로운 피처들을 개발할 필요가 없어지게된다.
Feast 의 컨셉
가장 윗단의 namespace 로 project 를 쓰고있는데 사용자가 이 project 내에서 하나 이상의 feature view 를 정의한다. 각 feature view 는 하나 이상의 피처들을 가지게된다. 이러한 피처들은 보통 하나 또는 두개 이상의 entity 가 된다. 피처 뷰는 항상 data source 를 가져야한다. 데이타소스는 훈련 데이타 소스를 만들때와 피처 값들을 온라인 스토어에 구체화 할 때 쓴다.
※ bold 표시는 아래에서 설명
.png?alt=media)
Project
프로젝트는 피처 스토어의 완전 격리를 인프라 수준에서 격리되는데 이는 리소스 네임스페이싱을 통해 달성이 된다. (테이블 이름들의 prefix를 프로젝트에 연관해서 매겨준다) 각 프로젝트는 완전 분리된 엔티티와 피처들의 모음이다. 하나의 요청으로 여러 프로젝트에서 피처들을 가져오는 것은 불가능하다. Feast 는 피처스토어 하나에 하나의 프로젝트를 환경(dev, staging, prod 와 같은)별로 가지는 것을 권장한다.
Data source
데이타 소스는 raw 데이타를 참조한다(예를들면 BigQuery 테이블).
Feast 는 시계열 데이타 모델로 데이타를 표현한다. 이 데이타 모델은 피처 데이타를 데이타 소스에서 해석해서 훈련 데이타로 만들거나 피처를 온라인 스토어로 만들기 위해 사용된다.
이해를 돕기 위해 예시로 아래 그림으로 나타내면, driver 라는 단일 엔티티와 두개의 피처들(trips_today, rating)을 가지고있는 형태
.png?alt=media)
어떻게 쓰면되나? (TBD)